作者:手机用户2502869883 | 来源:互联网 | 2023-07-26 16:54
本文介绍了爱奇艺被EMNLP2019接收的一篇论文。论文:FASPell:AFast,Adaptable,Simple,PowerfulChineseSpellCheckerBas
本文介绍了爱奇艺被 EMNLP 2019 接收的一篇论文。
论文:FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
开源链接:https://github.com/iqiyi/FASPell
“两个瓶颈”
自1990年代初期开展了一些开拓性工作以来,关于检测和纠正中文文本中的拼写错误的研究已过很长时间。然而,尽管在大多数研究中拼写错误已被简化为替换错误以及最近多个公开任务的努力,中文拼写检查仍然是一项困难的任务。而且,英语等类似语言的方法几乎不能直接用于中文,因为中文单词之间没有定界符,且单词缺乏形态上的变化,使得任何汉字的句法和语义解释都高度依赖其上下文。
几乎所有以前的中文拼写检查模型都部署了一个通用范式,其中将每个汉字的固定的相似字符集(称为困惑集或混淆集)用作候选项,然后用一个过滤器选择最佳候选项作为待纠错句子中的替换字符。这种朴素的设计面临两个主要瓶颈,而其负面影响未能在过去的提出的方案中得到缓解:
1.在稀缺的中文拼写检查数据上的过拟合问题由于中文拼写检查数据需要乏味繁冗的专业人力工作,因为一直资源不足。为了防止模型的过拟合,Wang等人(2018)提出了一种自动方法来生成伪拼写检查数据。但是,当生成的数据达到40k句子时,其拼写检查模型的精度不再提高。Zhao等人(2017)使用了大量的语言学规则来过滤候选项,但结果却比我们的表现差,尽管我们的模型没有利用任何语言学知识。
2.困惑集的使用所带来的汉字字符相似度利用上的不灵活性和不充分性问题。
困惑集因为是固定的,因此并非在任何语境、场景下都能包含正确候选项(一个比较极端的例子是,如果困惑集按照繁体中文制定,那么繁体中文的 “體”和“休”肯定不在困惑集的同一组相似字符中,但是在简体中文中对应的“体”和“休”缺是相似字符,如果错误文本中是把“休”写成了“体”,那么繁体中文困惑集下就无法检出,必须专门再制定一个简体困惑集才可以),这会极大降低检测的召回率(不灵活性问题);另外,困惑集中的字符的相似性的信息有损失,没有得到充分利用,因为一个字符在困惑集中相似字符是无差别对待的,然而事实上每两个字符间的相似度明显是有差别的,因此会影响检测的精确率(不充分性)。Zhang等人 (2015)提出了考虑了很多并没有字符相似度重要的特征(例如分词)来弥补字符相似度利用上的不充分性,但这会为其模型添加更多不必要的噪音。
论文概述
论文提出一个基于新范式的中文拼写检查器– FASPell。新的范式包括去噪自动编码(DAE)和解码器。与以前的SOTA模型相比,新范式使得我们的拼写检查器可以更快地进行计算,易于通用于简体或繁体、人类或机器产生的各类场景下的中文文本,结构更简单,错误检测和纠正性能更强大。这四点成就,是因为新的范式规避了两个瓶颈。第一,DAE通过利用无监督预训练方法(如BERT,XLNet,MASS等),减少了监督学习所需的中文拼写检查数据量(<10,000个句子)。第二,解码器有助于消除困惑集的使用,因为它在灵活和充分地利用汉字相似性这一关键特征上的不足。
论文贡献和方法
本论文提出通过更改中文拼写检查的范式来规避上述的两个瓶颈。作为主要贡献,并以我们在提出的中文拼写检查模型FASPell为例,这种新范式的最一般形式包括一个降噪自动编码器(DAE)和一个解码器。DAE生成可以将错误文本修改为正确文本的可能的候选项矩阵,解码器在这个矩阵中寻找最佳候选项路径作为输出。DAE因为可以在大规模正常语料数据上无监督训练而仅在中文拼写检查数据上fine-tune,避免了过拟合问题。另外,只要DAE足够强大,所有的语意上可能的候选字符都可以出现,且候选字符是根据周围语境即时生成的,这避免了困惑集所带来的不灵活性;解码器根据量化的字符相似度和DAE给出的字符的语境把握度来过滤出正确的替换字符,这样字符相似性上的细微差别信息都可以得到充分利用。
本文提出的模型FASPell中,DAE是由BERT中的掩码语言模型(MLM)来充当,解码器是本文提出的把握度-字符相似度解码器(CSD)来充当,如下如所示:

CSD中使用的量化的字符相似度也是本文提出的,较过去提出的字符相似度量化方法,我们的方法更加精准。我们在字形上采用Unicode标准的IDS表征,它可以准确描述汉字中的各个笔画和它们的布局形式,这使得即使是相同笔画和笔画顺序的(例如“田”与“由”,“午”与“牛”)的汉字之间也拥有不为1的相似度,与此相比,过去基于纯笔画或者五笔、仓颉编码的计算方法则粗糙很多。在字音上我们使用了所有的CJK语言中的汉字发音,尽管我们只是对中文文本检错纠错,但是实验证明考虑诸如粤语、日语音读、韩语、越南语的汉字发音对提高拼写检查的性能是有帮助的,而过去的方法均只考虑了普通话拼音。
CSD的训练阶段,利用训练集文本通过MLM输出的矩阵,逐行绘制语境把握度-字符相似度散点图,确定能将FP和 TP分开的最佳分界曲线。推理阶段,逐行根据分界线过滤掉FP得到TP结果,然后将每行的结果取并集得到最终替换结果。以前述图片为例,句子首先通过fine-tune训练好的MLM模型,得到的候选字符矩阵通过CSD进行解码过滤,第一行候选项中只有“主”字没有被CSD过滤掉,第二行只有“著”字未被过滤掉,其它行候选项均被分界线过滤清除,得到最终输出结果,即“苦”字被替换为为“著”,“丰”被替换为“主”。
论文实验和结果
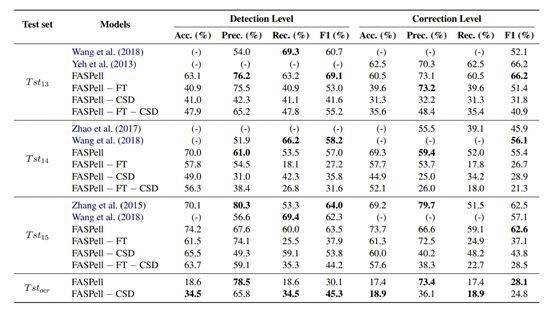
论文在4个数据集上分别进行了消融实验,证明了MLM的fine-tune和CSD分别对FASPell性能的贡献,实验也证明FASPell达到了SOTA的准确性。
点击阅读原文,获取论文全文!
end
也许你还想看
2019 ICME论文解析:爱奇艺首创实时自适应码率算法评估系统
干货|文本舆情挖掘的技术探索和实践

扫一扫下方二维码,更多精彩内容陪伴你!


![[编程题] LeetCode上的Dynamic Programming(动态规划)类型的题目](https://img1.php1.cn/3cd4a/24cea/42f/ab7ad6031d31eee4.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号